Hello, Internet. I want to talk to about about my website, taskboy.com, which has been in more or less continuous operations for almost 20 years.
As a professional full-stack web developer, taskboy.com has often been my playground to experiment with new ideas. It is now primarily a "resume" site with an attached blog.
Much of my professional work involves creating database-driven Model-View-Controller, n-tiered web applications for my employer's intranet. Which is why I have gone in exactly the opposite direction with taskboy.com, a site that features mostly static pages. The site is hosted on a debian virtual machine provided by Linode, with whom I have done business for the past decade without complaint. The web content is served by the venerable httpd server from the Apache foundation, which is still provides rock-solid performance along with a bounty of optional modules. I have a very simple apache configuration for taskboy.com (although there are other virtual hosts on the system as well).
Service Architecture
Just because the blog posts are static does not mean that I craft the HTML for each post by hand. Instead, I use a hacked version of Jason McIntosh's Plerd system to produce all the web content accessible through the blog site. Plerd watches a directory for new markdown files. When it sees them, it translates the markdown to HTML, wraps that HTML in existing HTML templates and writes the file to the docroot directory that apache serves to you when you access https://www.taskboy.com/. Plerd takes care of creating various Atom and JavaScript feeds for me.
Here's my attempt to describe the blog, notes, and image publishing architecture of taskboy.com:
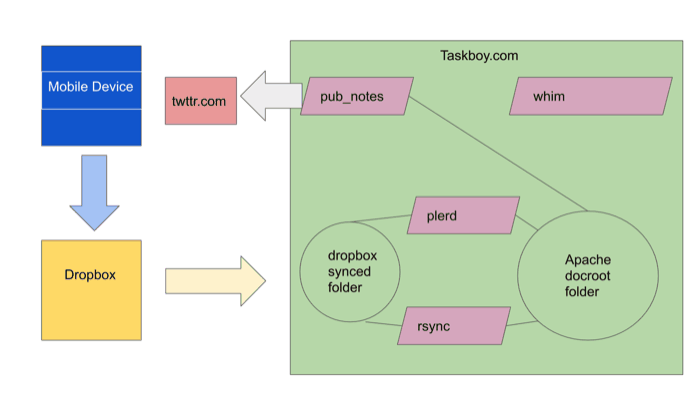
I use a customized version of Plerd. I made some modifications to the internal structures of Plerd, because jmac's version regenerates the entire site when it discovers new content. My version of Plerd rewrites only what it must (using a file system-based data store to maintain state) . I moved other bits of the software around for personal aesthetics. Also, I wanted my CSS and JS to be generated from Plerd templates along with blog content. This makes retheming the site very easy. Finally, I wanted to get rid of the plerdall daemon. This is the service that watches for directory changes. Instead, I have a cron that fires off plerdcmd (my own executable available in the forked project) that does much the same thing. Running out of cron just makes maintenance easier for me. I do not need to worry about restarting things when the machine reboots.
Another change was to make the client-side experience more dynamic. Because pages are regenerated only when needed, things like the recent posts side bar need to be generated when the page loads. Luckily, there was already a feed for the recent posts, so a little JS glue was need to insert that into the side bar.
It turns out that having JSON feeds actually powers quite a bit of Plerd. By "JSON Feed", I mean static JSON files accessible through a URL.
It is no secret that I have grown unhappy with the business models of social media. Being a greybeard, I remember when publishing on the web meant finding a public server, standing up a web server, and writing content for it. After about 10 years of messing with large social media sites, I realized I wanted to own my content again. Turns out, the folks at indieweb feel the same way.
Plerd already had many hooks ready for indieweb, but I wanted to understand it all better, which means experimenting with it myself.
Creating a static blog generator is not a new idea, even for me, who used perl and HTML::Mason to do this last time in the early aughties. However, Plerd has added a certain rigor to the process that was lacking before.
The frontend static of taskboy is built on Bootstrap, which I have gotten to know well because I have used it professionally for years now. Although Bootstrap requires jQuery, I am weaning off of that venerable shim library since modern EMCAScript has become widely adapted, capable and (mostly) sane. As I have mentioned in a previous post, I prefer to use JavaScript sparingly to enhance the user experience of the content rather than be a requirement to see any content on the site (although the sidebar of my blog does depend on, that is fairly optional content).
Authoring with Bear
What has really gotten me excited about blogging again is mobile devices. Sure, tablets and smartphones have been around for 10+ years now and laptops are Paleolithic atavisms, but found that I was quite happy to tweet on them for 10+ years. What changed? Two things.
First, I got really grumpy with Facebook's inability to control their own worst instincts about spying on me. In 2018, I deleted my account. In 2020, I felt like Twitter had become a company I worked for without being paid to do so.
Second, I discovered a text editor app for iOS that I really, really like called Bear. It's not a programmer's text editor, but it is a markdown-first text editor. It is easy to use, well-integrated with Dropbox, and pretty. When coupled with a decently sized bluetooth keyboard, it is actually quite pleasant to compose long documents like this!

Syncing to taskboy.com
Dropbox continues to support linux command line clients. This is perfect for my use-case. All my authoring platforms also support Dropbox.
When I am ready, I export my document from Bear to the right folder in Dropbox.
Handling pictures is easier than it has ever been, but that is mostly thanks to Dropbox, which is the hero of this story.
To publish pictures, I save photos to a directory on Dropbox. On taskboy, a periodically recurring process (aka cron) copies (actually rsyncs) all pictures there into the "img" directory of my docroot. Dead simple and crazy reliable.
Heck, here is the crontab entry:
*_60 * * * * rsync -ua $HOME_Dropbox_plerd_images/ $HOME_sites_www_www_img/
(Forgive the weirdly redundant */60. I was working around a small Bear issue.)
Publishing
It's only slightly more involved to publish blog posts and notes. To do so, I run this:
plerdcmd -P
This looks in two Dropbox folders. One folder contains blog posts as markdown files that need to be converted to HTML files. The other contains text files that will become notes. Either way, plerd writes the HTML files into the docroot. This runs every 3 minutes, so as not to encourage me not to spam readers. It also allows me a little window to catch typos.
Recently, I decided that I want to publish my notes to Twitter. I have written Twitter clients in the past, so that part wasn't hard. The program I wrote consumes the javascript feed of notes published by plerd and posts new notes to tweeter. It remembers what it already has published so as not to spam Twitter (hopefully).
Here is the mildly expurgated source code:
use Modern::Perl '2017'; use DBI; use Digest::MD5 'md5_hex'; use Getopt::Long; use HTML::Strip; use JSON; use Path::Class::File; use POSIX 'strftime'; use Twitter::API; our $gDBH; main(); sub usage { return \$opts{feedFile}, 'l|limit=i' => \$opts{limit}, 'q|query=s' => \$opts{query}, 'u|user=s' => \$opts{user}, 'v|verbose' => \$opts{verbose}, 'h|help' => \$opts{usage} ); if ($opts{usage}) { say usage(); exit; } dbValidate($opts{verbose}); if ($opts{query}) { return doQuery($opts{query}); } my ($twitter, $tokens) = getTwitterHandle($opts{user} || $ENV{USER}, $opts{verbose}); if (!defined $tokens) { die("Internal error [token recall failed]: rerun program."); } if ($opts{feedFile}) { if (!-e $opts{feedFile}) { die("Cannot find $opts{feedFile}\n"); } doPostsFromFeed($twitter, $tokens, $opts{feedFile}, $opts{limit}, $opts{verbose}); } } sub getTwitterHandle { my ($user, $verbose) = @_; my $client = Twitter::API->new_with_traits( traits => 'Enchilada', access_key => 'secret', access_secret => 'secret', consumer_key => "I've got a", consumer_secret => 'secret', ); my ($token_hash) = recallUserAccessTokens($user); if ($token_hash) { # This fatals if broken say "Testing cached user tokens" if $verbose; eval { $client->verify_credentials( { '-token' => $token_hash->{token}, '-token_secret' => $token_hash->{secret}, } ); 1; } or do { forgetUserAccessTokens($user); warn($@); say "These credenials no longer work. Please run $0 again."; exit; }; if ($verbose) { say "Cached access tokens for $user appear to be valid"; } return ($client, $token_hash); } say "Getting request token" if $verbose; my $request = $client->oauth_request_token; say "Getting auth URL" if $verbose; my $auth_url = $client->oauth_authorization_url({ oauth_token => $request->{oauth_token}, }); print "Authorize this application at: $auth_url\nThen, enter the returned PIN number displayed in the browser: "; my $pin = ; # wait for input chomp $pin; say ""; say "Getting access tokens for $user" if $verbose; my $access = $client->oauth_access_token( { token => $request->{oauth_token}, token_secret => $request->{oauth_token_secret}, verifier => $pin, } ); my ($token, $secret) = ($access->{'oauth_token'}, $access->{'oauth_token_secret'}); if (!($token && $secret)) { die("Did not get complete set of auth tokens for user $user. Rerun.\n"); } say "Recording access tokens" if $verbose; recordUserAccessTokens($user, $token, $secret); return ($client, recallUserAccessTokens($user)); } sub doQuery { my ($table) = @_; if ($table eq 'tokens') { return reportAccessTokens(); } elsif ($table eq 'publications') { return reportPublications(); } else { die("Unknown table '$table'"); } } sub doPostsFromFeed { my ($twitter, $tokens, $feedFile, $limit, $verbose) = @_; my $feed = JSON::from_json(Path::Class::File->new($feedFile)->slurp()); my $published = 0; for my $item (reverse @{ $feed->{items} }) { my $cleanedContent = cleanContentForTwitter($item); if ($verbose) { say "Post will be:\n—\n$cleanedContent\n—"; } my $pub = recallPublication(\$item->{content_html}); if ($pub) { if ($verbose) { say "Already published this. Skipping"; } next; } else { eval { my $response = $twitter->update( $cleanedContent, { -token => $tokens->{token}, -token_secret => $tokens->{secret}, } ); 1; } or do { say $@; next; }; recordPublication($tokens->{username}, $item->{content_html}); $published += 1; if (defined $limit && $published >= $limit) { if ($verbose) { say "Published the maximum number ($limit) of posts to Twitter."; } last; } } } return 1; } sub cleanContentForTwitter { my ($feedItem) = @_; my $continuation = "…"; my ($noteUrl, $content) = ($feedItem->{url}, $feedItem->{content_html}); $content = HTML::Strip->new->parse($content); my @words = split(/ /, $content); return if !@words; my $linkBack = "\n\nLink: $noteUrl"; my $maxLen = 280 - length($linkBack); my $cleaned = ""; while (@words) { my $word = shift @words; my $proposed = $cleaned . "$word "; if (length($proposed) > $maxLen) { if (@words) { $cleaned = $cleaned . "$word$continuation"; } last; } $cleaned = $proposed; } $cleaned .= $linkBack; return $cleaned; } sub recordUserAccessTokens { my ($user, $token, $secret) = @_; return if !($user && $token && $secret); my $db = dbConnect(); my $now = time(); my $result = $db->selectall_arrayref("SELECT 1 FROM tokens WHERE username=" . $db->quote($user)); if ($result->[0]->[0]) { my $sql = "UPDATE tokens SET token=?, secret=?, updated_at=? WHERE username=?"; my $sth = $db->prepare($sql); return $sth->execute($token, $secret, $now, $user); } my $sql = "INSERT INTO tokens (username, token, secret, created_at, updated_at) VALUES (?, ?, ?, ?, ?)"; my $sth = $db->prepare($sql); return $sth->execute($user, $token, $secret, $now, $now); } sub recallUserAccessTokens { my ($user) = @_; return unless $user; my $db = dbConnect(); my $sql = "SELECT * FROM tokens WHERE username=" . $db->quote($user); my $sth = $db->prepare($sql); $sth->execute; my $row = $sth->fetchrow_hashref; return if !$row || !$row->{username}; return { token => $row->{token}, secret => $row->{secret}, username => $row->{username}, }; } sub forgetUserAccessTokens { my ($user) = @_; return unless $user; my $db = dbConnect(); my $sql = "DELETE FROM tokens WHERE username=" . $db->quote($user); my $sth = $db->prepare($sql); return $sth->execute; } sub reportAccessTokens { my $db = dbConnect(); my $sql = "SELECT * FROM tokens"; my $sth = $db->prepare($sql); $sth->execute; while (my $row = $sth->fetchrow_hashref) { printf( "%-8s: created: %s, last updated: %s\n", $row->{username}, u2pretty($row->{created_at}), u2pretty($row->{updated_at}), ); } } sub recordPublication { my ($username, $content) = @_; return if !($username && $content); my $now = time(); my $db = dbConnect(); my $content_hash = md5_hex($content); if (my $row = recallPublication($content_hash)) { my $sql = "UPDATE publications SET published_at=?,updated_at=? WHERE id=?"; my $sth = $db->prepare($sql); return $sth->execute($now, $now, $row->{content_hash}); } my $sql = 'INSERT INTO publications (username, content_hash, published_at, created_at, updated_at) VALUES (?, ?, ?, ?, ?)'; my $sth = $db->prepare($sql); return $sth->execute($username, $content_hash, $now, $now, $now); } # end sub recordPublication sub recallPublication { my ($content_hash) = @_; if (ref $content_hash) { # This is the content we need to hash $content_hash = md5_hex($$content_hash); } my $db = dbConnect(); my $sql = "SELECT * FROM publications WHERE content_hash=" . $db->quote($content_hash); my $sth = $db->prepare($sql); $sth->execute; my $row = $sth->fetchrow_hashref; $sth->finish; return if !$row || !$row->{content_hash}; return $row; } sub forgetPublication { my ($content_hash) = @_; my $db = dbConnect(); my $sql = "DELETE FROM publications WHERE content_hash=" . $db->quote($content_hash); my $sth = $db->prepare($sql); return $sth->execute; } # end sub forgetPublication sub reportPublications { my $db = dbConnect(); my $sql = "SELECT * FROM publications ORDER BY username, created_at DESC"; my $sth = $db->prepare($sql); $sth->execute; while (my $row = $sth->fetchrow_hashref) { printf( "%-8s: hash: %s, published: %s\n", $row->{username}, $row->{content_hash}, u2pretty($row->{published_at}), ); } } sub u2pretty { my ($unix_epoch_ts) = @_; my @parts = localtime($unix_epoch_ts); my $fmt = '%Y-%m-%d %H:%M:%S'; return strftime($fmt, @parts); } sub dbFile { my $dbfile = Path::Class::File->new("$ENV{HOME}_.plerd_db/twitter_pub.db"); return $dbfile; } sub dbConnect { if (defined $gDBH) { return $gDBH; } my $dbfile = dbFile(); return $gDBH = DBI->connect("dbi:SQLite:dbname=" . $dbfile, "", "", { AutoCommit => 1, RaiseError => 1 }); } sub dbTableSchema { return ( 'CREATE TABLE publications (id INT AUTOCREMENT PRIMARY KEY, username CHAR(8), content_hash TEXT, published_at INTEGER, created_at INTEGER, updated_at INTEGER)', 'CREATE TABLE tokens (id INT AUTOCREMENT PRIMARY KEY, username CHAR(8), token TEXT, secret TEXT, created_at INTEGER, updated_at INTEGER)', ); } sub dbInstall { my $dbfile = dbFile(); if (-e $dbfile) { die("$dbfile exists. Halt. Remove file to force reinstall.\n"); } if (!-d $dbfile->dir) { $dbfile->dir->mkpath || die("mkdir failed: $?"); } my $db = dbConnect(); for my $table (dbTableSchema()) { $db->do($table); } return 1; } sub dbUninstall { my $dbfile = dbFile(); $dbfile->remove(); } sub dbValidate { my $dbfile = dbFile(); if (-e $dbfile) { my $db = dbConnect(); my $missing = 0; for my $known_table ('publications', 'tokens') { my $result = $db->selectall_arrayref("SELECT 1 FROM sqlite_master WHERE type='table' AND name=" . $db->quote($known_table)); if (!$result->[0]->[0]) { $missing = 1; warn "Appears that $known_table is not defined.\n"; } } die("DB file exists, but tables appear to be missing\n") if $missing; } else { say "Creating a data store."; dbInstall(); } return 1; }
I post the code here for those of a hackerish disposition. Note that you need to create an app on twitter's dev site to get all the secret keys and such for three-legged authentication to work.
Plerd supports webmentions to the extent that blog and note entries use the h-entry microformat. Sending and receiving web mentions are handled through Jmac's other nifty project, whim. Plerd also inserts headers into the HTML to lets consumers of the web content know where to push web mentions too.
Because whim is a mojolicious app server, I chose to run it behind a reverse proxy in apache. Why? I wanted pretty URLs and I wanted to use SSL for the blog and web mention traffic. Using the very excellent let's encrypt tools, getting valid certs for apache and configuring httpd to use them was easy.
My plerd uses whim as a REST service to figure out if a blog post has web mentions and to display the content of same. This last feature took a lot of combing out of the reverse proxy configuration, but it now works.
What started as a simple static site generator has morphed into a medium-complexity contraption which also is easy to maintain and reasonable secure.
Now, if I stop working on the Plerd infrastructure, I can focus on making the stock layout of the app a little more pleasant.